
电脑爬虫经常出现错误的原因分析(探究电脑爬虫错误的背后原因及解决方法)
 游客
游客 摘要:
随着互联网的快速发展,电脑爬虫已成为各种应用场景中不可或缺的工具。然而,电脑爬虫在实际运行过程中经常会遇到各种错误,这不仅严重影响了其稳定性和准确性,也给用户带来了不便。本文将探讨...
摘要:
随着互联网的快速发展,电脑爬虫已成为各种应用场景中不可或缺的工具。然而,电脑爬虫在实际运行过程中经常会遇到各种错误,这不仅严重影响了其稳定性和准确性,也给用户带来了不便。本文将探讨... 随着互联网的快速发展,电脑爬虫已成为各种应用场景中不可或缺的工具。然而,电脑爬虫在实际运行过程中经常会遇到各种错误,这不仅严重影响了其稳定性和准确性,也给用户带来了不便。本文将探讨电脑爬虫常见错误的原因,并提出一些解决方法,旨在帮助读者更好地理解和运用电脑爬虫。

网络连接问题导致的错误
电脑爬虫在进行数据抓取时需要依赖网络连接,如果网络不稳定或者出现断网情况,就容易导致爬虫错误。此时,可以通过设置重连机制或者使用代理IP来解决该问题。
网站反爬机制引发的错误
为了防止恶意抓取和保护数据安全,很多网站都设置了反爬机制,如验证码、访问频率限制等。这些机制对于正常爬虫来说是一种挑战,经常会导致错误的发生。为了应对这些反爬机制,可以使用模拟人类操作的策略,如设置随机访问间隔、使用不同的User-Agent等。
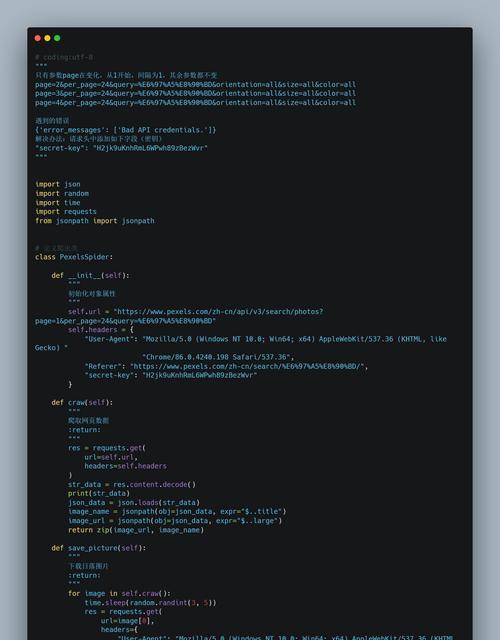
页面结构变化导致的错误
网站在更新迭代过程中会对页面结构进行调整,这样就会导致原有的爬虫无法正确解析网页内容,从而出现错误。解决这个问题的方法是定期监测目标网站,并及时更新爬虫代码以适应页面结构的变化。
数据解析错误
爬虫在抓取到网页内容后,需要对其进行解析并提取所需的数据。然而,由于网页内容的复杂性和多样性,解析过程往往容易出错。为了提高解析准确性,可以使用强大的HTML解析库,并编写灵活的解析规则。
异常数据处理不当导致的错误
在爬虫运行过程中,难免会遇到一些异常情况,如无效的链接、404错误等。如果不正确处理这些异常情况,就容易导致爬虫错误。为了避免这种情况,可以设置异常处理机制,并及时记录和处理异常数据。
反爬策略更新导致的错误
随着技术的不断发展,网站的反爬策略也在不断更新。爬虫需要及时跟进这些变化,否则就会因为无法绕过新的反爬机制而出现错误。为了解决这个问题,可以订阅相关技术社区或论坛,及时获取最新的反爬策略。
用户代理被封禁导致的错误
一些网站会根据用户代理来判断是否为爬虫,如果频繁使用相同的用户代理进行访问,很容易被封禁。为了避免这个问题,可以使用IP代理池和随机用户代理进行请求,增加爬虫的隐蔽性。
运行环境配置问题导致的错误
电脑爬虫在运行过程中需要依赖特定的运行环境,如Python版本、相关库的安装等。如果环境配置不正确,就会导致爬虫无法正常运行。解决这个问题的方法是根据爬虫的需求进行环境配置,并且及时更新相关依赖库。
内存溢出导致的错误
如果爬虫处理的数据量过大,且没有合理管理内存,就容易出现内存溢出的错误。为了避免这个问题,可以使用分页处理数据、定期释放内存等策略来优化内存使用。
日志记录不完善导致的错误追踪困难
在爬虫出现错误时,通过日志记录可以更好地追踪错误的原因。然而,如果日志记录不完善,就会给错误排查带来困难。在编写爬虫代码时应该充分考虑日志的记录与管理。
代理IP失效导致的错误
使用代理IP可以提高爬虫的匿名性和稳定性,但是代理IP也存在失效的情况。如果选择的代理IP失效了,就会导致爬虫无法正常工作。解决这个问题的方法是定期检测代理IP的可用性,并及时更新。
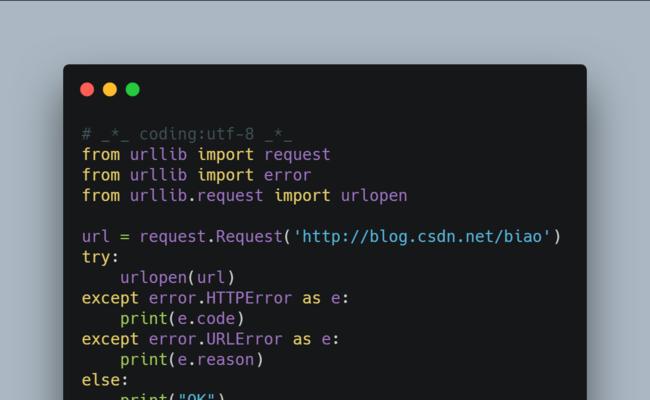
请求超时导致的错误
由于网络环境等原因,爬虫在进行请求时可能会出现超时情况。如果没有适当处理这种超时情况,就容易导致爬虫错误。为了解决这个问题,可以设置适当的超时时间,并根据情况进行重试或异常处理。
反爬策略识别不准确导致的错误
有些网站会采用隐蔽的反爬策略,如动态渲染、异步加载等,这对于普通的爬虫来说是一种挑战。如果反爬策略的识别不准确,就会导致爬虫错误。为了解决这个问题,可以使用一些高级技术,如无头浏览器或者JavaScript解析引擎。
被封禁IP导致的错误
如果爬虫频繁访问同一网站,或者没有合理控制访问频率,就容易被网站封禁IP。被封禁后,爬虫将无法正常工作。为了避免被封禁,可以合理设置请求频率、使用代理IP等方式来规避网站的封禁策略。
缺乏异常处理机制导致的错误
在编写爬虫代码时,如果没有考虑到各种异常情况的处理,就会导致爬虫错误。为了提高爬虫的稳定性和健壮性,应该编写完善的异常处理机制,并及时处理各种异常情况。
电脑爬虫在实际运行过程中经常出现错误,这与网络连接问题、网站反爬机制、页面结构变化、数据解析错误等多方面因素有关。为了提高电脑爬虫的稳定性和准确性,我们可以采取一系列措施,如设置重连机制、使用代理IP、定期更新爬虫代码等。只有正确分析错误的原因,并采取适当的解决方法,才能更好地应对电脑爬虫错误。
作者:游客本文地址:https://www.kinghero.com.cn/post/8821.html发布于 09-11
文章转载或复制请以超链接形式并注明出处智酷天地